
Apologies for the delay. It took longer than I expected to have the file and a stable internet connection at the same time. You’ll find the notes on the SlideShare page.
Tag: Digital media
IL 2012: Discovery Systems

Speaker: Bob Fernekes
The Gang of Four: Google, Apple, Amazon, & Facebook
Google tends to acquire companies to grow the capabilities of it. We all know about Apple. Amazon sells more ebooks than print books now. Facebook is… yeah. That.
And then we jump to selecting a discovery service. You would do that in order to make the best use of the licensed content. This guy’s library did a soft launch in the past year of the discovery service they chose, and it’s had an impact on the instruction and tools (i.e. search boxes) he uses.
And I kind of lost track of what he was talking about, in part because he jumped from one thing to the next, without much of a transition or connection. I think there was something about usability studies after they implemented it, although they seemed to focus on more than just the discovery service.
Speaker: Alison Steinberg Gurganus
Why choose a discovery system? You probably already know. Students lack search skills, but they know how to search, so we need to give them something that will help them navigate the proprietary stuff we offer out on the web.
The problem with the discovery systems is that they are very proprietary. They don’t quite play fairly or nicely with competitor’s content yet.
Our users need to be able to evaluate, but they also need to find the stuff in the first place. A great discovery service should be self-explanatory, but we don’t have that yet.
We have students who understand Google, which connects them to all the information and media they want. We need something like that for our library resources.
When they were implementing the discovery tool, they wanted to make incremental changes to the website to direct users to it. They went from two columns, with the left column being text links to categories of library resources and services, to three columns, with the discover search box in the middle column.
When they were customizing the look of the discovery search results, they changed the titles of items to red (from blue). She notes that users tend to ignore the outside columns because that’s where Google puts advertisements, so they are looking at ways to make that information more visible.
I also get the impression that she doesn’t really understand how a discovery service works or what it’s supposed to do.
Speaker: Athena Hoeppner
Hypothesis: discovery includes sufficient content of high enough quality, with full text, and …. (didn’t type fast enough).
Looked at final papers from a PhD level course (34), specifically the methodology section and bibliography. Searched for each item in the discovery search as well as one general aggregator database and two subject-specific databases. The works cited were predominately articles, with a significant number of web sources that were not available through library resources. She was able to find more citations in the discovery search than in Google Scholar or any of the other library databases.
Clearly the discovery search was sufficient for finding the content they needed. Then they used a satisfaction survey of the same students that covered familiarity and frequency of use for the subject indexes, discovery search, and Google Scholar. Ultimately, it came down that the students were satisfied and happy with the subject indexes, and too few respondents to get a sense of satisfaction with the discovery search or Google Scholar.
Conclusions: Students are unfamiliar with the discovery system, but it could support their research needs. However, we don’t know if they can find the things they are looking for in it (search skills), nor do we know if they will ultimately be happy with it.
musings on web-scale discovery systems

My library is often on the forefront of innovation, having the advantage of a healthy budget and staff size, yet small enough to be nimble. Frequently, when my colleagues return from conferences and give their reports, they’ll conclude with something along the lines of “we’re already doing most of the things they talked about.” At a recent conference report session, that was repeated again, with one exception: we have not implemented a web-scale discovery system.
I’m of two minds about web-scale discovery systems. In theory, they’re pretty awesome, allowing users to discover all of the content available to them from the library, regardless of the source or format. But in reality, they’re hamstrung by exclusive deals and coding limitations. The initial buzz was that they caused a dramatic increase in the use of library resources, but a few years in, and I’m hearing conflicting reports and grumblings.
We held off on buying a web-scale discovery system for two main reasons: one, we didn’t have the funding secured, and two, most of the reference librarians felt indifferent to outright dislike towards the systems out there at the time. We’re now in the process of reviewing and evaluating the current systems available, after many discussions about which problems we are hoping they will solve.
In the end, they really aren’t “Google for Libraries.” We think that our users want a single search box, but do they really? I heard an anecdote about how the library had spent a lot of time teaching users where to find their web-scale discovery system, making sure it was visible on the main library page, etc. After a professor assigned the same students to find a known article (gave them the full citation) using the web-scale discovery system (called it by name), the most frequent question the library got was, “How do I google the <name of web-scale discovery system>?”
I wonder if the ROI really is significant enough to implement and promote a web-scale discovery system? These systems are not cheap, and they take a bit of labor to maintain them. And, frankly, if the battle over exclusive content continues to be waged, it won’t be easy to pick the best one for our collection/users and know that it will stay that way for more than six months or a year.
Does your library have a web-scale discovery system? Is it everything you thought it would be? Would you pick the same one if you had to choose again?
my twitter infographic
 It’s a mashup of two of my favorite things — data visualization and social media. Of course I’m going to make one.
It’s a mashup of two of my favorite things — data visualization and social media. Of course I’m going to make one.
The interesting thing is that for some reason I come across as a gamer according to the algorithms. Unless you count solitaire, sudoku, and Words with Friends, I’m not really a gamer at all. The PS2, games, and accessories I bought from my sister last November that is are sitting in a corner unassembled are also a testament to how little I game.
Anyway, click on the image to get the full-sized view, and if you make your own, be sure to share the link in the comments.
library day in the life round 6
I plan on using Twitter and Flickr to capture my week this time. CoverItLive will show the tweets below, and you can follow my Flickr feed or check the widget under CiL to see what I’ve posted there.
www.flickr.com
|
it could be worse
Have you noticed the changes Google has been making to the way they display search results? Google Instant has been the latest, but before that, there was the introduction of the “Everything” sidebar. And that one in particular seems to have upset numerous Google search fans. If you do a search in Google for “everything sidebar,” the first few results are about removing or hiding it.
Not only that, but the latest offering from the Funny Music Project is a song all about hating the Google “Everything” sidebar. The creator, Jesse Smith, expresses a frustration that many of us can identify with, “It’s hard to find a product that does what it does really well. In a world of mediocrity, it’s the exception that excels. Then some jerk has to justify his job by tinkering and jiggering and messing up the whole thing.”
Tech folks like to tinker. We like making things work better, or faster, or be more intuitive. I’ll bet that there are a lot of Google users who didn’t know about the different kinds of content-specific searches that Google offered, or had never used the advanced search tools. And they’re probably happy with the introduction of the “Everything” sidebar.
But there’s another group of folks who are evidently very unhappy with it. Some say it takes up too much room on the screen, that it adds complexity, and that they just don’t like the way it looks.
Cue ironic chuckling from me.
Let’s compare the Google search results screen with search results from a few of the major players in libraryland:
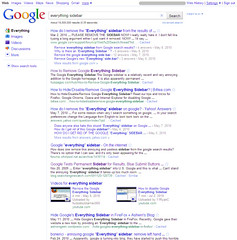
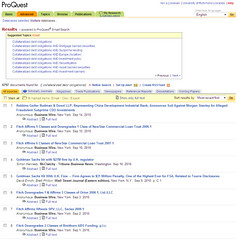
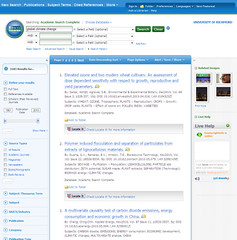
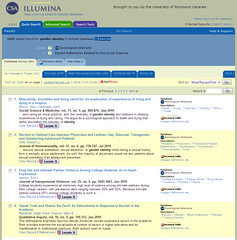
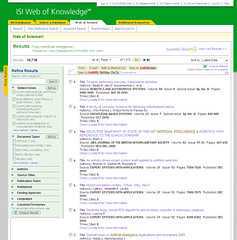
So, who’s going to write a song about how much they hate <insert library database platform of choice>?
CIL 2009: New Strategies for Digital Natives
Speaker: Helene Blowers
Begins with a video of a 1yo. unlocking and starting up a Preschool Adventure game on an iPhone, and then paging through images in the photo gallery. Joey is a digital native and the future of library users.
Digital natives are those born after 1980. When they were 1, IBM distributed the first commercial PC. Cellular phones were introduced at the age of 3. By the time they were 14, the internet was born.
Web 1.0 was built on finding stuff, Web 2.0 was built on connecting with other users and share information. Digital natives are used to not only having access to the world through the internet, but also engaging with it.
Business Week categorized users by how they interact with the internet and their generation. This clearly lays out the differences between how the generations use this tool, and it should inform the way we approach library services to them.
Digital native realities:
- Their identity online is the same as their in-person identity. They grew up with developing both at the same time, as oppose to those who came before. Facebook, MySpace, Twitter, Flixster, and LinkedIn are the top five online social networks, according to a report in January. How many of them do you have an identity in?
- The ability to create and leave your imprint somewhere is important to digital natives. According to the Pew Internet & American Life, those who participate in social networks are more likely to create unique content than those who do not.
- We are seeing a shift from controlled information to collaborative information, so digital information quality has become important and a personal responsibility to digital natives. After a study showed that Wikipedia was as accurate as Britannica resulted in EB adding a wiki layer to their online presence.
- Digital natives have grown up in a world they believe to be safe, whether it is or not. Less than 0.08% of students say that they have met someone online without their parents knowledge, and about 65% say that they ignored or deleted strangers that tried to contact them online. However, that doesn’t stop them from intentionally crossing that line in order to rebel against rules.
- Digital opportunity is huge. There are no barriers, the playing field has been leveled, access is universal, connection ubiquitous, and it’s all about me.
- Digital sharing is okay. It’s just sharing. They aren’t concerned with copyright or ownership. Fanfic, mashups, remixes, parodies… Creative Commons has changed the way we look at ownership and copyright online.
- Privacy online and in their social networks is not much of a concern. Life streams aggregate content from several social networks, providing the big picture of someone’s online life.
- What you do online makes a difference — digital advocacy. This was clear during the US presidential election last year.
What does this mean for libraries? How do we use this to support the information needs of our users?
Think about ways to engage with virtual users — what strategies do we need in order to connect library staff and services with users in meaningful ways? Think about ways to enrich the online experience of users that then enhances their experiences in the physical library and their daily lives. Think about ways to empower customers to personalize and add value to their library experience so that they feel good about themselves and their community.
DILO: electronic resources librarian
9:00am Arrive at work. Despite getting to bed early, I still overslept. Great way to start a Monday, I tell you.
9:00-9:20am I was out of the office for most of last week, so I spent some time catching up with my assistant. This also gave my computer plenty of time to boot up.
9:20-9:30am Logged into the network, and then went to get some iced tea from the library coffee shop. It takes several minutes for all of the start-up programs to load, so that’s a perfect time to acquire my first dose of work-time caffeine.
9:30-9:35am Start this post.
9:35-10:20am Sifting through the 100+ new messages in my mailbox from the time while I was gone. I followed-up on the ones that looked urgent while I was out, but the rest were left for today. In the end, three messages went into the to-do category and a few more into the use statistics category. The rest were read and deleted.
10:20-10:45am Filled out an order form for a new database. PDF form is printable only, so this required the use of a typewriter (my handwriting is marginally legible). I also discovered in the middle of the process that I did not have all of the necessary information, which required further investigation and calculations.
10:45-11:05am Sent email reminders to the students LIB 101 class that I will be teaching on Friday. Created a class roster for all four sections I’m teaching this spring.
11:05-11:15am Mental break. Read Twitter and left a birthday greeting for a friend in Facebook.
11:15-11:20am Added use stats login info for a new resource to our ERM and the shared spreadsheet of admin logins that we have been using since before the ERM (still implementing ERM, so it’s best to put it in both places).
11:20-11:25am Processed incoming email.
11:25am-12:40pm Was going to run some errands over my lunch hour, but instead was snagged by some colleagues who were going out to my favorite Mexican restaurant.
12:40-1:00pm Sorting through the email that came in while I was gone. Answered a call from a publisher sales person.
1:00-3:00pm Main Service Desk shift, covering the reference side of it. During the slow times, I accessed my work station PC via remote desktop and worked on the scanned license naming standardization project I started last week. In the process, I’m also breaking apart multiple contracts that were accidentally scanned together. As usual, the busy times involved a sudden influx of in-person, email, and IM questions, most often at the same time.
3:00-3:15pm Got a refill of ice tea from the coffee shop, processed email, and read through the Twitter feed.
3:15-4:00pm Organized recently scanned license agreements and created labels for the folders. Filed the licenses in the file drawer next to my cubicle.
4:00-4:20pm Checked in with co-workers and revised my to-do list.
4:20-5:15pm Responded to email and followed-up on action items related to the recent NASIG executive board meeting.
And that, my friends, is my rather unusual day in the life of an electronic resources librarian. Most of the time, I bounce between actual ER work, meetings, and email.
nasig 2008
I am getting ready to fly out to Phoenix early (too early) tomorrow morning for the NASIG annual conference (and executive board meeting). The conference begins on Thursday, but my session blogging probably won’t start until Friday. Posts will be erratic and coming in several at once, most likely, because I won’t be able to upload them until I’m back in my room. We’d like to have free wifi in the conference area, but the Hilton charges more than it costs to fill your gas tank and then some, which is well beyond what this intimate conference can afford to provide.
If you’d like to see what others have to say about NASIG 2008, be sure to check out our nifty little Netvibes page. Kudos to Steve Lawson, who inspired me to put that together this year. If you are attending the conference and plan to blog or post photos on Flickr, be sure to use the nasig2008 tag!
unvocab debut
I made my debut on Uncontrolled Vocabulary the other evening. Everyone on the call were folks I had met at one point while at Computers in Libraries last week, and it kind of made my heart ache a little less to hear them all again. I called in on the ShoePhone, but it was glitchy, and I probably won’t use it again. Dunno if it was a TalkShoe problem or a ClearWire problem, but I think my cell phone would sound better.
So, go listen to the episode and revel in our memories of CiL!